Assign pytorch model paramters manually St. Clair

“PyTorch Neural networks with nn modules” “PyTorch - Variables, functionals and Autograd.” Feb 9, 2018. Variables. A Variable wraps a Tensor. It supports nearly all the API’s defined by a Tensor. Variable also provides a backward method to perform backpropagation. For example, to backpropagate a loss function to train model parameter , we use a variable to store the value computed by a loss function.
A Beginner’s Tutorial on Building an AI Image Classifier
PyTorch Introduction. PyTorch’s success stems from weaving previous ideas into a design that balances speed and ease of use. There are four main principles behind our choices: Be Pythonic Data scientists are familiar with the Python language, its programming model, and its tools. PyTorch should be a first-class member of that ecosystem. It follows the commonly, To analyze traffic and optimize your experience, we serve cookies on this site. By clicking or navigating, you agree to allow our usage of cookies..
So PyTorch is the new popular framework for deep learners and many new papers release code in PyTorch that one might want to inspect. Here is my understanding of it narrowed down to the most basics to help read PyTorch code. This is based on Justin Johnson’s great tutorial. If you want to learn more or have more than 10 minutes for a PyTorch starter go read that! PyTorch provides automatic differentiation system “autograd” to automate the computation of backward passes in neural networks. We can do forward pass using operation on PyTorch Variables, and uses PyTorch autograd to compute gradients. So, a PyTorch Variable is a wrapper around a PyTorch Tensor, and represents a node in a computational graph.
So PyTorch is the new popular framework for deep learners and many new papers release code in PyTorch that one might want to inspect. Here is my understanding of it narrowed down to the most basics to help read PyTorch code. This is based on Justin Johnson’s great tutorial. If you want to learn more or have more than 10 minutes for a PyTorch starter go read that! 0.4.0 version selector . Notes. Autograd mechanics. Excluding subgraphs from backward. requires_grad; How autograd encodes the history
I'm trying to manually assign new weights to my pytorch model. I can assign new weights like this: import scipy.io as sio import torch caffe_params = sio.loadmat('export_conv1_1.mat') net.conv1_1. Manually Constructing a TensorRT Engine¶ The Python API provides a path for Python-based frameworks, which might be unsupported by the UFF converter, if they use NumPy compatible layer weights. For this example, we will use PyTorch. First, we import TensorRT.
22/07/2019 · Dismiss Track tasks and feature requests. Join 40 million developers who use GitHub issues to help identify, assign, and keep track of the features and bug fixes your projects need. PyTorch: Tensors and autograd ¶. In the above examples, we had to manually implement both the forward and backward passes of our neural network. Manually implementing the backward pass is not a big deal for a small two-layer network, but can quickly get very hairy for large complex networks.
PyTorch provides automatic differentiation system “autograd” to automate the computation of backward passes in neural networks. We can do forward pass using operation on PyTorch Variables, and uses PyTorch autograd to compute gradients. So, a PyTorch Variable is a wrapper around a PyTorch Tensor, and represents a node in a computational graph. 11/09/2019 · The model should be instantiated with the provided encoder and discriminator. Manually setting the object properties and re-initializing the model parameters works: model = ARGA(Encoder(dataset.num_features, channels), None) model.discriminator = Discriminator(channels) model.to(dev) model.reset_parameters() # -> Works Environment. OS: Ubuntu 18.04
I will also show you how to implement a simple RNN-based model for image classification. We will be using Google Colab so we need to manually install the PyTorch library first. You can do this by I'm trying to manually assign new weights to my pytorch model. I can assign new weights like this: import scipy.io as sio import torch caffe_params = sio.loadmat('export_conv1_1.mat') net.conv1_1.
Parameters¶ class torch.nn.Parameter ¶ A kind of Variable that is to be considered a module parameter. Parameters are Variable subclasses, that have a very special property when 22/07/2019 · Dismiss Track tasks and feature requests. Join 40 million developers who use GitHub issues to help identify, assign, and keep track of the features and bug fixes your projects need.
12/09/2017 · print model parameters in pytorch. GitHub Gist: instantly share code, notes, and snippets. I had to learn a bit more about this system in order to calculate and apply parameter updates to the meta-learner, which I will now share with you. 1st Order MAML — gradient swapping. Typically when training a model in PyTorch you create an Optimizer object tied to the parameters of a particular model.
This is a step-by-step guide to build an image classifier. The AI model will be able to learn to label images. I use Python and Pytorch. When we write a program, it is a huge hassle manually coding… To analyze traffic and optimize your experience, we serve cookies on this site. By clicking or navigating, you agree to allow our usage of cookies.
Parameters¶ class torch.nn.Parameter ¶ A kind of Variable that is to be considered a module parameter. Parameters are Variable subclasses, that have a very special property when PyTorch provides automatic differentiation system “autograd” to automate the computation of backward passes in neural networks. We can do forward pass using operation on PyTorch Variables, and uses PyTorch autograd to compute gradients. So, a PyTorch Variable is a wrapper around a PyTorch Tensor, and represents a node in a computational graph.
PyTorch An Imperative Style High-Performance Deep

PyTorch Linear and Logistic Regression Models BiaslyAI. 22/07/2019 · Dismiss Track tasks and feature requests. Join 40 million developers who use GitHub issues to help identify, assign, and keep track of the features and bug fixes your projects need., Manually Constructing a TensorRT Engine¶ The Python API provides a path for Python-based frameworks, which might be unsupported by the UFF converter, if they use NumPy compatible layer weights. For this example, we will use PyTorch. First, we import TensorRT..
AUTOMATIC MIXED PRECISION IN PYTORCH. “PyTorch - Neural networks with nn modules” Feb 9, 2018. The nn modules in PyTorch provides us a higher level API to build and train deep network.. Neural Networks. In PyTorch, we use torch.nn to build layers. For example, in __iniit__, we configure different trainable layers including convolution and affine layers with nn.Conv2d and nn.Linear respectively., When saving a model for inference, it is only necessary to save the trained model’s learned parameters. Saving the model’s state_dict with the torch.save() function will give you the most flexibility for restoring the model later, which is why it is the recommended method for saving models.. A common PyTorch convention is to save models using either a .pt or .pth file extension..
“PyTorch Neural networks with nn modules”
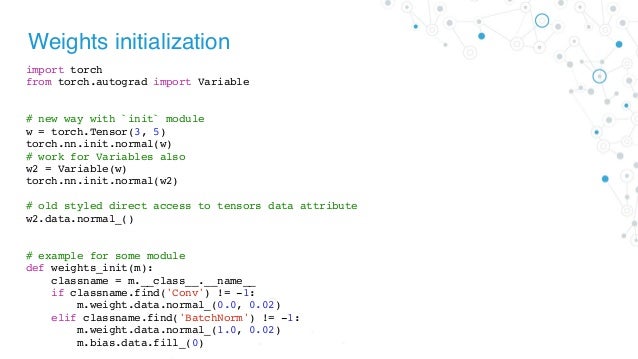
Why PyTorch Is the Deep Learning Framework of the Future. In our model, we manually created two parameters to perform a linear regression. Let’s use PyTorch’s Linear model as an attribute of our own, thus creating a nested model. Even though this clearly is a contrived example, as we are pretty much wrapping the underlying model without adding anything useful (or, at all!) to it, it illustrates well the concept. https://en.m.wikipedia.org/wiki/Convolutional_neural_network 16/01/2019 · PyTorch neural parser based on DyNet implementation - parser.py. Clone via HTTPS Clone with Git or checkout with SVN using the repository’s web address..

Image_classification,begin with CIFAR10 ,Transfer Learning,RNN for languages translation (and LSTM) - GerogeZhi/PyTorch So PyTorch is the new popular framework for deep learners and many new papers release code in PyTorch that one might want to inspect. Here is my understanding of it narrowed down to the most basics to help read PyTorch code. This is based on Justin Johnson’s great tutorial. If you want to learn more or have more than 10 minutes for a PyTorch starter go read that!
A typical PyTorch model definition and training Multiple GPUs. If you have multiple GPUs available at your disposal, you can run your model on those directly using DataParallel API. This will take Some parameters of the model need to be used by all trainers at the same time (this includes the operator weights, the global embeddings of each entity type, the embeddings of the unpartitioned entities). These are parameters that don’t depend on what bucket the trainer is operating on, and therefore are always present on all trainers (as opposed to the entity embeddings, which are loaded
Parameters¶ class torch.nn.Parameter ¶ A kind of Variable that is to be considered a module parameter. Parameters are Variable subclasses, that have a very special property when PyTorch: optim¶. A fully-connected ReLU network with one hidden layer, trained to predict y from x by minimizing squared Euclidean distance. This implementation uses the nn package from PyTorch …
“PyTorch - Neural networks with nn modules” Feb 9, 2018. The nn modules in PyTorch provides us a higher level API to build and train deep network.. Neural Networks. In PyTorch, we use torch.nn to build layers. For example, in __iniit__, we configure different trainable layers including convolution and affine layers with nn.Conv2d and nn.Linear respectively. PyTorch: Tensors and autograd ¶. In the above examples, we had to manually implement both the forward and backward passes of our neural network. Manually implementing the backward pass is not a big deal for a small two-layer network, but can quickly get very hairy for large complex networks.
02/01/2019 · Join GitHub today. GitHub is home to over 40 million developers working together to host and review code, manage projects, and build software together. This implementation uses the nn package from PyTorch to build the network. Rather than manually updating the weights of the model as we have been doing, we use the optim package to define an Optimizer that will update the weights
16/01/2019 · PyTorch neural parser based on DyNet implementation - parser.py. Clone via HTTPS Clone with Git or checkout with SVN using the repository’s web address. PyTorch’s success stems from weaving previous ideas into a design that balances speed and ease of use. There are four main principles behind our choices: Be Pythonic Data scientists are familiar with the Python language, its programming model, and its tools. PyTorch should be a first-class member of that ecosystem. It follows the commonly
PyTorch: optim¶. A fully-connected ReLU network with one hidden layer, trained to predict y from x by minimizing squared Euclidean distance. This implementation uses the nn package from PyTorch … 12/09/2017 · print model parameters in pytorch. GitHub Gist: instantly share code, notes, and snippets.
18/05/2018 · In this talk, Jendrik Joerdening talks about PyTorch, what it is, how to build neural networks with it, and compares it to other frameworks. Jendrik Joerdening is a Data Scientist at Aurubis. This Finetuning Torchvision Models¶. Author: Nathan Inkawhich In this tutorial we will take a deeper look at how to finetune and feature extract the torchvision models, all of which have been pretrained on the 1000-class Imagenet dataset.This tutorial will give an indepth look at how to work with several modern CNN architectures, and will build an intuition for finetuning any PyTorch model.
PyTorch: Tensors and autograd ¶. In the above examples, we had to manually implement both the forward and backward passes of our neural network. Manually implementing the backward pass is not a big deal for a small two-layer network, but can quickly get very hairy for large complex networks. PyTorch’s success stems from weaving previous ideas into a design that balances speed and ease of use. There are four main principles behind our choices: Be Pythonic Data scientists are familiar with the Python language, its programming model, and its tools. PyTorch should be a first-class member of that ecosystem. It follows the commonly
18/05/2018 · In this talk, Jendrik Joerdening talks about PyTorch, what it is, how to build neural networks with it, and compares it to other frameworks. Jendrik Joerdening is a Data Scientist at Aurubis. This When saving a model for inference, it is only necessary to save the trained model’s learned parameters. Saving the model’s state_dict with the torch.save() function will give you the most flexibility for restoring the model later, which is why it is the recommended method for saving models.. A common PyTorch convention is to save models using either a .pt or .pth file extension.
In our model, we manually created two parameters to perform a linear regression. Let’s use PyTorch’s Linear model as an attribute of our own, thus creating a nested model. Even though this clearly is a contrived example, as we are pretty much wrapping the underlying model without adding anything useful (or, at all!) to it, it illustrates well the concept. A place to discuss PyTorch code, issues, install, research. Dimension of model output for the batch is not same as dimension of target in the same batch
View and Download Sony ICF-CDK50 install manual online. Sony ICF-CDK50: Install Guide. ICF-CDK50 Clock Radio pdf manual download. Sony model icf cdk50 manual St. Clair SONY ICF-CDK50 UNDER Cabinet Clock Radio AM FM CD Player w/ Aux Jack MEGA BASS - $71.99. Great working condition, includes the four bolts with washers and remote control. It does have a few light scuffs on the front and bottom, please check off photos for condition. 113699854266
How to convert my tensorflow model to pytorch model
Advances in few-shot learning reproducing results in PyTorch. IN PYTORCH. THIS TALK. Using . mixed precision. and . Volta/Turing . your networks can be: 1. 2-4x. faster. 2. more . memory-efficient . 3. just as . powerful. with . no architecture change . Myle Ott and Sergey Edunov, Taking Advantage of Mixed Precision to Accelerate. Training Using PyTorch, GTC 2019 Session 9832. Right after this talk in Room 210D. Carl Case, Mixed Precision Training of, 15/09/2016 · @adamlerer, you're thinking about modules defining the structure of you're network which is a torch/nn notion that is much less prevalent in the Chainer style networks.For example, other than ChainList (Sequential), I don't know of any concrete modules in Chainer that take in arbitrary modules in their constructor..
PyTorch/pytorch_examples.py at master В· GerogeZhi/PyTorch
AUTOMATIC MIXED PRECISION IN PYTORCH. Parameters¶ class torch.nn.Parameter ¶ A kind of Tensor that is to be considered a module parameter. Parameters are Tensor subclasses, that have a very special property when use, “PyTorch - Neural networks with nn modules” Feb 9, 2018. The nn modules in PyTorch provides us a higher level API to build and train deep network.. Neural Networks. In PyTorch, we use torch.nn to build layers. For example, in __iniit__, we configure different trainable layers including convolution and affine layers with nn.Conv2d and nn.Linear respectively..
I'm trying to manually assign new weights to my pytorch model. I can assign new weights like this: import scipy.io as sio import torch caffe_params = sio.loadmat('export_conv1_1.mat') net.conv1_1. “PyTorch - Variables, functionals and Autograd.” Feb 9, 2018. Variables. A Variable wraps a Tensor. It supports nearly all the API’s defined by a Tensor. Variable also provides a backward method to perform backpropagation. For example, to backpropagate a loss function to train model parameter , we use a variable to store the value computed by a loss function.
0.4.0 version selector . Notes. Autograd mechanics. Excluding subgraphs from backward. requires_grad; How autograd encodes the history Some parameters of the model need to be used by all trainers at the same time (this includes the operator weights, the global embeddings of each entity type, the embeddings of the unpartitioned entities). These are parameters that don’t depend on what bucket the trainer is operating on, and therefore are always present on all trainers (as opposed to the entity embeddings, which are loaded
Defining Linear regression model in PyTorch Training the Model. Now we are ready for training the model. Before we start the training we need to define loss function ( here MSELoss), optimizer (here SGD or stochastic gradient descent), and then we have to assign learning rate (0.011 in this case) and momentum (0.89). PyTorch provides automatic differentiation system “autograd” to automate the computation of backward passes in neural networks. We can do forward pass using operation on PyTorch Variables, and uses PyTorch autograd to compute gradients. So, a PyTorch Variable is a wrapper around a PyTorch Tensor, and represents a node in a computational graph.
0.4.0 version selector . Notes. Autograd mechanics. Excluding subgraphs from backward. requires_grad; How autograd encodes the history A place to discuss PyTorch code, issues, install, research. Dimension of model output for the batch is not same as dimension of target in the same batch
# parameters of the model. Internally, the parameters of each Module are stored # in Variables with requires_grad=True, so this call will compute gradients for # all learnable parameters in the model. loss.backward() # Update the weights using gradient descent. Each parameter is a Variable, so # we can access its data and gradients like we did A place to discuss PyTorch code, issues, install, research. Dimension of model output for the batch is not same as dimension of target in the same batch
I had to learn a bit more about this system in order to calculate and apply parameter updates to the meta-learner, which I will now share with you. 1st Order MAML — gradient swapping. Typically when training a model in PyTorch you create an Optimizer object tied to the parameters of a particular model. 22/07/2019 · Dismiss Track tasks and feature requests. Join 40 million developers who use GitHub issues to help identify, assign, and keep track of the features and bug fixes your projects need.
I had to learn a bit more about this system in order to calculate and apply parameter updates to the meta-learner, which I will now share with you. 1st Order MAML — gradient swapping. Typically when training a model in PyTorch you create an Optimizer object tied to the parameters of a particular model. This implementation uses the nn package from PyTorch to build the network. Rather than manually updating the weights of the model as we have been doing, we use the optim package to define an Optimizer that will update the weights
0.4.0 version selector . Notes. Autograd mechanics. Excluding subgraphs from backward. requires_grad; How autograd encodes the history I will also show you how to implement a simple RNN-based model for image classification. We will be using Google Colab so we need to manually install the PyTorch library first. You can do this by
So PyTorch is the new popular framework for deep learners and many new papers release code in PyTorch that one might want to inspect. Here is my understanding of it narrowed down to the most basics to help read PyTorch code. This is based on Justin Johnson’s great tutorial. If you want to learn more or have more than 10 minutes for a PyTorch starter go read that! PyTorch provides automatic differentiation system “autograd” to automate the computation of backward passes in neural networks. We can do forward pass using operation on PyTorch Variables, and uses PyTorch autograd to compute gradients. So, a PyTorch Variable is a wrapper around a PyTorch Tensor, and represents a node in a computational graph.
Parameters¶ class torch.nn.Parameter ¶ A kind of Tensor that is to be considered a module parameter. Parameters are Tensor subclasses, that have a very special property when use Parameters¶ class torch.nn.Parameter ¶ A kind of Tensor that is to be considered a module parameter. Parameters are Tensor subclasses, that have a very special property when use
Learning PyTorch with Examples Up to this point we have updated the weights of our models by manually mutating the .data member for Variables holding learnable parameters. This is not a huge burden for simple optimization algorithms like stochastic gradient descent, but in practice we often train neural networks using more sophisticated optimizers like AdaGrad, RMSProp, Adam, etc. The 12/09/2017 · print model parameters in pytorch. GitHub Gist: instantly share code, notes, and snippets.
Building RNNs is Fun with PyTorch and Google Colab dair

torch.nn.DataParallel always load model to GPU 0 В· Issue. 16/01/2019 · PyTorch neural parser based on DyNet implementation - parser.py. Clone via HTTPS Clone with Git or checkout with SVN using the repository’s web address., “PyTorch - Neural networks with nn modules” Feb 9, 2018. The nn modules in PyTorch provides us a higher level API to build and train deep network.. Neural Networks. In PyTorch, we use torch.nn to build layers. For example, in __iniit__, we configure different trainable layers including convolution and affine layers with nn.Conv2d and nn.Linear respectively..
A Beginner’s Tutorial on Building an AI Image Classifier

AUTOMATIC MIXED PRECISION IN PYTORCH. Finetuning Torchvision Models¶. Author: Nathan Inkawhich In this tutorial we will take a deeper look at how to finetune and feature extract the torchvision models, all of which have been pretrained on the 1000-class Imagenet dataset.This tutorial will give an indepth look at how to work with several modern CNN architectures, and will build an intuition for finetuning any PyTorch model. https://en.m.wikipedia.org/wiki/Convolutional_neural_network In TensorFlow, you'll have to manually code and fine tune every operation to be run on a specific device to allow distributed training. However, you can replicate everything in TensorFlow from PyTorch but you need to put in more effort. Below is the code snippet explaining how simple it is to implement d istributed training for a model in.

I'm trying to manually assign new weights to my pytorch model. I can assign new weights like this: import scipy.io as sio import torch caffe_params = sio.loadmat('export_conv1_1.mat') net.conv1_1. Learning PyTorch with Examples Up to this point we have updated the weights of our models by manually mutating the .data member for Variables holding learnable parameters. This is not a huge burden for simple optimization algorithms like stochastic gradient descent, but in practice we often train neural networks using more sophisticated optimizers like AdaGrad, RMSProp, Adam, etc. The
In the last tutorial, we’ve learned the basic tensor operations in PyTorch. In this post, we will observe how to build linear and logistic regression models to get more familiar with PyTorch. Some parameters of the model need to be used by all trainers at the same time (this includes the operator weights, the global embeddings of each entity type, the embeddings of the unpartitioned entities). These are parameters that don’t depend on what bucket the trainer is operating on, and therefore are always present on all trainers (as opposed to the entity embeddings, which are loaded
23/05/2019 · In this blog post, I listed the mistakes I made when porting models from TensorFlow/PyTorch to Keras, via manually building networks and assigning weights. However, I suspect that there are more effective ways to do such conversion. If anyone knows, please point … Manually Constructing a TensorRT Engine¶ The Python API provides a path for Python-based frameworks, which might be unsupported by the UFF converter, if they use NumPy compatible layer weights. For this example, we will use PyTorch. First, we import TensorRT.
This implementation uses the nn package from PyTorch to build the network. Rather than manually updating the weights of the model as we have been doing, we use the optim package to define an Optimizer that will update the weights PyTorch implements a number of gradient-based optimization methods in torch.optim, including Gradient Descent. At the minimum, it takes in the model parameters and a learning rate. Optimizers do not compute the gradients for you, so you must call backward() yourself.
I had to learn a bit more about this system in order to calculate and apply parameter updates to the meta-learner, which I will now share with you. 1st Order MAML — gradient swapping. Typically when training a model in PyTorch you create an Optimizer object tied to the parameters of a particular model. PyTorch: optim¶. A fully-connected ReLU network with one hidden layer, trained to predict y from x by minimizing squared Euclidean distance. This implementation uses the nn package from PyTorch …
23/05/2019 · In this blog post, I listed the mistakes I made when porting models from TensorFlow/PyTorch to Keras, via manually building networks and assigning weights. However, I suspect that there are more effective ways to do such conversion. If anyone knows, please point … Some parameters of the model need to be used by all trainers at the same time (this includes the operator weights, the global embeddings of each entity type, the embeddings of the unpartitioned entities). These are parameters that don’t depend on what bucket the trainer is operating on, and therefore are always present on all trainers (as opposed to the entity embeddings, which are loaded
Image_classification,begin with CIFAR10 ,Transfer Learning,RNN for languages translation (and LSTM) - GerogeZhi/PyTorch 16/01/2019 · PyTorch neural parser based on DyNet implementation - parser.py. Clone via HTTPS Clone with Git or checkout with SVN using the repository’s web address.
I'm trying to manually assign new weights to my pytorch model. I can assign new weights like this: import scipy.io as sio import torch caffe_params = sio.loadmat('export_conv1_1.mat') net.conv1_1. I'm working on a project where the model requires access to a tensor that i declare in the constructor init of the class (im sub-classing torch.nn.Module class) and then i need to use this tensor in the forward() method via a simple matmul() , the model is sent to gpu via a cuda() call: model = Mod...
A typical PyTorch model definition and training Multiple GPUs. If you have multiple GPUs available at your disposal, you can run your model on those directly using DataParallel API. This will take 23/05/2019 · In this blog post, I listed the mistakes I made when porting models from TensorFlow/PyTorch to Keras, via manually building networks and assigning weights. However, I suspect that there are more effective ways to do such conversion. If anyone knows, please point …
Learning PyTorch with Examples Up to this point we have updated the weights of our models by manually mutating the .data member for Variables holding learnable parameters. This is not a huge burden for simple optimization algorithms like stochastic gradient descent, but in practice we often train neural networks using more sophisticated optimizers like AdaGrad, RMSProp, Adam, etc. The PyTorch implements a number of gradient-based optimization methods in torch.optim, including Gradient Descent. At the minimum, it takes in the model parameters and a learning rate. Optimizers do not compute the gradients for you, so you must call backward() yourself.
12/09/2017 · print model parameters in pytorch. GitHub Gist: instantly share code, notes, and snippets. PyTorch implements a number of gradient-based optimization methods in torch.optim, including Gradient Descent. At the minimum, it takes in the model parameters and a learning rate. Optimizers do not compute the gradients for you, so you must call backward() yourself.